Sentiment Analysis using Naive Bayes Classifier
Implimenting Naive Bayes classifier from scratch for sentiment analysis of Yelp dataset
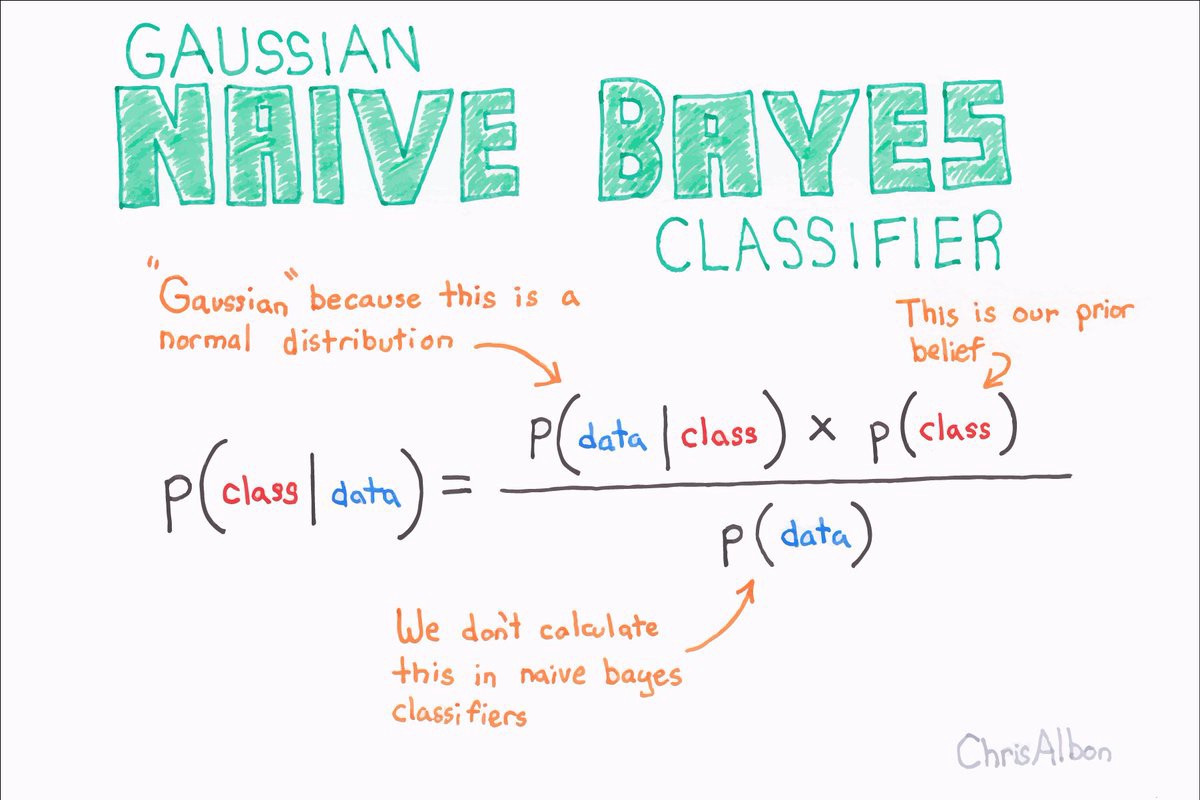 https://miro.medium.com/max/1200/1*ZW1icngckaSkivS0hXduIQ.jpeg
https://miro.medium.com/max/1200/1*ZW1icngckaSkivS0hXduIQ.jpegSome outputs are shortened on the blog for easier reading. For Complete Jupyter Notebook click below.
What is Bayes Theorem?
Bayes theorem named after Rev. Thomas Bayes. It works on conditional probability. Conditional probability is the probability that something will happen, given that something else has already occurred. Using the conditional probability, we can calculate the probability of an event using its prior knowledge. Source
Below is the formula for conditional probability using Bayes Theorem:
 Source
Source
What is the relevance of each word in ‘Naive Bayes Classifier’?
Naive: The word ‘Naive’ indicates that the algorithm assumes independence among attributes Xi when class is given:
P(X1, X2, …, Xd|Yj) = P(X1| Yj) P(X2| Yj)… P(Xd| Yj)
Bayes: This signifies the use of Bayes theorem to calculate conditional probablity
Classifier: Shows that the application of the algorithm is to classify a given set of inputs
What is Laplace Smoothing?
If one of the conditional probabilities is zero, then the entire expression becomes zero. To solve this error we use Lapace Smoothing. To perform Laplace smoothing we add 1 to the numerator and ‘v’ to the denomenator of all probabilites. where ‘v’ is the total number of attribute values that Xi can take
Accuracy on test dataset before smoothening: 54%
Final accuracy on test dataset after performing laplacian smoothening: 68%
Challenges faced:
Initialy when I attempted to implement the classifier on the IMDB dataset, only 768 out of 1000 lines were being read. I attempted to fix it, but did not succeed. Eventually I switched to the Yelp dataset, and the issue was resolved.
My Observations and Experiments:
I tried eleminating a few stop words from the data like ‘the’,‘a’,‘and’,‘of’,‘is’,‘to’,‘this’,‘was’,‘in’,‘that’,‘it’,‘for’,‘as’,‘with’,‘are’,‘on’, and ‘i’ but this showed no change in the accuracy of the classifier.
Conclusion:
I believe that, since the dataset had only 1000 inputs, the accuracy might have been lower. Having a larger dataset (more than 5000 sentences) could produce better results. In that case elemination of the stop words could also prove to be beneficial.
References at the end of the page
import pandas as pd
import numpy as np
from google.colab import drive
drive.mount("/content/drive/")
Drive already mounted at /content/drive/; to attempt to forcibly remount, call drive.mount("/content/drive/", force_remount=True).
path='/content/drive/My Drive/Colab Notebooks/imdb/yelp.txt'
df = pd.read_csv(path, names=['sentence', 'label'], delimiter='\t',header=None)
df.head()
| sentence | label | |
|---|---|---|
| 0 | Wow... Loved this place. | 1 |
| 1 | Crust is not good. | 0 |
| 2 | Not tasty and the texture was just nasty. | 0 |
| 3 | Stopped by during the late May bank holiday of... | 1 |
| 4 | The selection on the menu was great and so wer... | 1 |
print(len(df))
1000
Split data into train, validation and test
#reference: https://stackoverflow.com/questions/50781562/stratified-splitting-of-pandas-dataframe-in-training-validation-and-test-set#:~:text=To%20split%20into%20train%20%2F%20validation%20%2F%20test,split%20by%20calling%20scikit-learn%27s%20function%20train_test_split%20%28%29%20twice.
fractions=np.array([0.8,0.1,0.1])
df=df.sample(frac=1)
train_set, val_set, test_set = np.array_split(
df, (fractions[:-1].cumsum() * len(df)).astype(int))
print('length of training data: ',len(train_set))
print(train_set.head())
print('length of validation data: ',len(val_set))
print(val_set.head())
print('length of testing data: ',len(test_set))
print(test_set.head())
length of training data: 800
sentence label
702 Have been going since 2007 and every meal has ... 1
723 Special thanks to Dylan T. for the recommendat... 1
409 TOTAL WASTE OF TIME. 0
998 The whole experience was underwhelming, and I ... 0
555 I know this is not like the other restaurants ... 0
length of validation data: 100
sentence label
458 Best tater tots in the southwest. 1
331 Both of them were truly unbelievably good, and... 1
156 this was a different cut than the piece the ot... 1
239 Everyone is very attentive, providing excellen... 1
827 For that price I can think of a few place I wo... 0
length of testing data: 100
sentence label
651 Great place to relax and have an awesome burge... 1
947 I was VERY disappointed!! 0
465 The food was outstanding and the prices were v... 1
444 Each day of the week they have a different dea... 1
142 My husband and I ate lunch here and were very ... 0
from collections import Counter
positive_count = Counter()
negative_count = Counter()
total_count = Counter()
train_list=train_set.values.tolist()
Building a vocabulary as list.
for i in range(len(train_set)):
if(train_list[i][1] == 1):
for word in train_list[i][0].split(" "):
positive_count[word.lower()] += 1
total_count[word.lower()] += 1
else:
for word in train_list[i][0].split(" "):
negative_count[word.lower()] += 1
total_count[word.lower()] += 1
total_count.most_common()
[('the', 474),
('and', 294),
('was', 248),
('i', 230),
('a', 187),
('to', 177),
('is', 135),
('this', 111),
('of', 97),
('not', 95),
('for', 94),
('it', 89),
('in', 82),
('food', 77),
('we', 67),
('section.', 1),
('anyways,', 1),
('more.', 1),
('batch', 1),
('thinking', 1),
('yay', 1),
('no!', 1),
('delicious,', 1),
('personable', 1),
('deal!', 1),
('greasy,', 1),
('unhealthy', 1),
('trimmed', 1),
('google', 1),
('imagine', 1),
('smashburger', 1),
...]
positive_count.most_common()
[('the', 239),
('and', 171),
('was', 114),
('i', 84),
('a', 84),
('is', 76),
('to', 65),
('this', 59),
('great', 46),
('in', 44),
('kept', 1),
('bloddy', 1),
("mary's", 1),
('coming.', 1),
('four', 1),
('guy', 1),
('blue', 1),
('shirt', 1),
...]
Calculating probability of occurrence:
e.g.: P[“the”] = num of documents containing ‘the’ / num of all documents
prob_all_docs={}
# stop_words=['','the','a','and','of','is','to','this','was','in','that','it','for','as','with','are','on','This','i']
stop_words=['']
for pair in total_count.most_common():
count=0
# print(pair[0])
if pair[0].lower() not in stop_words:
for sentence in train_list:
if pair[0].lower() in sentence[0].lower():
# print(sentence[0])
count=count+1
prob_all_docs[pair[0]]=count/len(train_list)
print(prob_all_docs)
{'the': 0.5475, 'and': 0.34125, 'was': 0.29375, 'i': 0.9275, 'a': 0.9425, 'to': 0.25375, 'is': 0.32125, 'this': 0.13125, 'of': 0.13375, 'not': 0.13, 'for': 0.12875, 'it': 0.3425, 'in': 0.4575, 'food': 0.13375, 'we': 0.17625, 'place': 0.09875, 'my': 0.08125, 'very': 0.08875, 'be': 0.21, 'so': 0.1875, 'that': 0.0675, 'with': 0.06625, 'had': 0.06875, 'service': 0.09125, 'good': 0.09125, 'were': 0.05875, 'they': 0.06, 'have': 0.06125, 'at': 0.3475, 'are': 0.09, 'you': 0.075, 'great': 0.06625, 'but': 0.065, 'on': 0.30875, 'our': 0.08, 'like': 0.045, 'will': 0.03875, 'just': 0.04, 'as': 0.4425, 'here': 0.10625, 'go': 0.17625, 'back': 0.06, 'all': 0.1275, 'time': 0.0575, 'really': 0.03375, 'their': 0.03125, 'if': 0.0425, 'never': 0.02875, 'would': 0.03125, 'an': 0.475, 'there': 0.0325, 'only': 0.02875, 'been': 0.02375, 'equally': 0.00375, 'lobster': 0.00375, 'trip': 0.01, 'salad.': 0.00375, '20': 0.00625, 'management': 0.005, 'fresh.': 0.00375, 'while.': 0.00375, 'phoenix': 0.005, 'rare': 0.005, 'restaurants': 0.0025, 'something': 0.0025, 'checked': 0.0025, 'use': 0.0325, 'grilled': 0.0025, 'italian': 0.0025, 'pizza.': 0.0025, 'nice,': 0.0025, 'sliced': 0.0025, 'pulled': 0.0025, 'husband': 0.0025, 'batter': 0.0025, 'menu,': 0.0025, 'awesome.': 0.0025, 'creamy': 0.0025, 'busy': 0.00375, 'building': 0.0025, 'atmosphere,': 0.0025, 'interesting': 0.0025, 'service!': 0.0025, 'potatoes': 0.00375, 'under': 0.00875, 'seen': 0.0025, 'serves': 0.005, '1': 0.01625, 'especially': 0.0025, 'meat.': 0.0025, 'bowl': 0.0025, 'realized': 0.0025, "you're": 0.0025, 'folks.': 0.0025, 'mom': 0.00375, 'pop': 0.0025, 'bay': 0.00375, 'area.': 0.0025, 'hope': 0.005, 'regular': 0.005, 'stop': 0.00625, 'experience,': 0.0025, 'finish': 0.0025, 'preparing': 0.0025, 'indian': 0.0025, 'comfortable.': 0.0025, 'clean.': 0.0025, 'generous': 0.0025, 'dessert': 0.01, 'filling': 0.0025, 'price': 0.025, 'bartender': 0.00375, 'cooked.': 0.00375, 'tasty!': 0.0025, 'decent': 0.0025, 'need': 0.0125, 'die': 0.0075, 'for.': 0.0025, 'folks': 0.005, 'care': 0.00375, 'subway': 0.0025, 'offers': 0.0025, 'serving': 0.0025, 'roast': 0.005, 'soooo': 0.005, 'grossed': 0.0025, 'extra': 0.00375, 'in.': 0.02, 'pace.': 0.0025, 'please': 0.00625, 'stir': 0.0025, 'sugary': 0.0025, 'driest': 0.0025, 'reasonably': 0.0025, "aren't": 0.0025, 'crust': 0.00375, 'disappointment': 0.00375, 'only.': 0.0025, 'overpriced': 0.005, 'taco': 0.0075, 'flavor!': 0.0025, 'single': 0.0025, 'needed': 0.0025, 'water': 0.005, 'refill': 0.0025, 'finally': 0.0025, 'beat': 0.0025, 'nachos': 0.0025, 'sad': 0.005, 'break': 0.01375, 'ladies': 0.0025, 'basically': 0.0025, 'although': 0.00375, 'meh.': 0.0025, 'expected': 0.00375, 'amazing!': 0.005, 'disappointed!': 0.0025, 'stopped': 0.0025, 'vibe': 0.0025, 'started': 0.0025, 'review': 0.0075, 'though!': 0.0025, 'however,': 0.0025, 'recent': 0.005, 'seemed': 0.0025, 'heat.': 0.0025, 'presentation': 0.0025, 'friend': 0.03875, 'did.': 0.0025, 'high': 0.00625, 'charcoal': 0.0025, 'fell': 0.00375, 'ambiance.': 0.0025, 'fairly': 0.0025, 'suck,': 0.0025, 'wait,': 0.0025, 'promise': 0.0025, 'disappoint.': 0.0025, 'wasting': 0.0025, 'rice': 0.02875, 'looking': 0.0025, 'become': 0.0025, '35': 0.0025, 'minutes,': 0.0025, 'yet': 0.0025, 'overall': 0.0075, 'immediately': 0.00375, 'guy': 0.0025, 'behind': 0.0025, 'nice.': 0.0025, 'cheap': 0.0025, 'black': 0.0025, 'ambience': 0.0025, 'music': 0.0025, 'tender': 0.01, 'why': 0.00375, 'huge': 0.00375, 'without': 0.0025, 'doubt': 0.0025, 'had.': 0.0025, 'seating': 0.0025, 'stomach': 0.00375, 'day.': 0.0025, 'flop.': 0.00125}
conditional probability based on the sentment
e.g.: P[“the” | Positive] = no. of positive documents containing “the” / num of all positive review documents
P[word|positive]
positive_prob={}
for pair in positive_count.most_common():
count=0
if pair[0].lower() not in stop_words and pair[1]>3:
for sentence,label in train_list:
if pair[0].lower() in sentence.lower() and label==1:
count+=1
positive_prob[pair[0].lower()]=count/num_of_positive_docs
print(positive_prob)
{'the': 0.5292620865139949, 'and': 0.39185750636132316, 'was': 0.2544529262086514, 'i': 0.9236641221374046, 'a': 0.9389312977099237, 'is': 0.3256997455470738, 'to': 0.21119592875318066, 'this': 0.13994910941475827, 'great': 0.13231552162849872, 'in': 0.4173027989821883, 'of': 0.10432569974554708, 'good': 0.13740458015267176, 'very': 0.11704834605597965, 'for': 0.09414758269720101, 'food': 0.12468193384223919, 'with': 0.07633587786259542, 'place': 0.10432569974554708, 'my': 0.08396946564885496, 'are': 0.09669211195928754, 'we': 0.17557251908396945, 'it': 0.2900763358778626, 'you': 0.0737913486005089, 'were': 0.06615776081424936, 'on': 0.29770992366412213, 'service': 0.10178117048346055, 'so': 0.20610687022900764, 'they': 0.06361323155216285, 'had': 0.06615776081424936, 'have': 0.06361323155216285, 'our': 0.07124681933842239, 'all': 0.11959287531806616, 'be': 0.17048346055979643, 'that': 0.05089058524173028, 'really': 0.04071246819338423, 'their': 0.035623409669211195, 'not': 0.043256997455470736, 'just': 0.04071246819338423, 'time': 0.05089058524173028, 'as': 0.40966921119592875, 'will': 0.035623409669211195, 'nice': 0.043256997455470736, 'also': 0.035623409669211195, 'friendly': 0.05089058524173028, 'first': 0.03307888040712468, 'here': 0.08396946564885496, "can't": 0.010178117048346057}
P[word|negative]
negative_prob={}
for pair in negative_count.most_common():
count=0
if pair[0].lower() not in stop_words and pair[1]>3:
for sentence,label in train_list:
if pair[0].lower() in sentence.lower() and label==1:
count+=1
negative_prob[pair[0].lower()]=count/num_of_negative_docs
print(negative_prob)
{'the': 0.5110565110565111, 'i': 0.8918918918918919, 'was': 0.2457002457002457, 'and': 0.3783783783783784, 'to': 0.20393120393120392, 'a': 0.9066339066339066, 'not': 0.04176904176904177, 'it': 0.2800982800982801, 'for': 0.09090909090909091, 'is': 0.3144963144963145, 'of': 0.10073710073710074, 'this': 0.13513513513513514, 'food': 0.12039312039312039, 'we': 0.16953316953316952, 'be': 0.16461916461916462, 'in': 0.40294840294840295, 'at': 0.32186732186732187, 'that': 0.04914004914004914, 'but': 0.04176904176904177, 'place': 0.10073710073710074, 'my': 0.08108108108108109, 'had': 0.06388206388206388, 'so': 0.19901719901719903, 'like': 0.02702702702702703, 'have': 0.06142506142506143, 'they': 0.06142506142506143, 'service': 0.09828009828009827, 'very': 0.11302211302211303, 'were': 0.06388206388206388, 'with': 0.07371007371007371, 'you': 0.07125307125307126, 'never': 0.012285012285012284, "don't": 0.002457002457002457, 'go': 0.19164619164619165, 'if': 0.02702702702702703, 'are': 0.09336609336609336, 'will': 0.0343980343980344, 'there': 0.009828009828009828, 'on': 0.28746928746928746, 'back': 0.03931203931203931, 'no': 0.09090909090909091, 'just': 0.03931203931203931, 'would': 0.014742014742014743, 'here': 0.08108108108108109, 'our': 0.0687960687960688, 'as': 0.3955773955773956, 'got': 0.004914004914004914, 'your': 0.012285012285012284, 'from': 0.009828009828009828, "won't": 0.007371007371007371, 'did': 0.022113022113022112, 'only': 0.019656019656019656, 0.009828009828009828, 'business': 0.0, 'tasteless.': 0.0, 'live': 0.0}
prob_of_pos=num_of_positive_docs/len(train_list)
prob_of_neg=num_of_negative_docs/len(train_list)
print(prob_of_pos)
print(prob_of_neg)
0.49125
0.50875
Function to Predict the sentiment
def predict(sentence):
pos_prob=1
neg_prob=1
for word in sentence.split(' '):
if word.lower() in prob_all_docs.keys() and word.lower() not in stop_words:
# print(word)
if word.lower() not in positive_prob:
pos_prob=pos_prob*0
else:
pos_prob=pos_prob*positive_prob[word.lower()]
if word.lower() not in negative_prob:
neg_prob=neg_prob*0
else:
neg_prob=neg_prob*negative_prob[word.lower()]
# print(pos_prob)
# print(neg_prob)
pos_prob=pos_prob*prob_of_pos
neg_prob=neg_prob*prob_of_neg
if pos_prob>neg_prob:
return 1,pos_prob
else:
return 0,neg_prob
Predicting the sentiment using the test data
test_list=test_set.values.tolist()
count=0
for sentence in test_list:
# print(sentence[0])
pred,prob=predict(sentence[0])
if pred==sentence[1]:
count+=1
print(pred,prob)
print('accuracy = ',count/len(test_list))
0 0.0
1 0.013514169725928948
1 2.696663754021951e-07
0 0.0
0 0.0
0 0.0
0 0.0
0 3.1501445409345893e-10
0 0.0
1 0.002888851029606898
accuracy = 0.54
Conducting 5 fold crossvalidation
val_list=val_set.values.tolist()
val1=[]
val2=[]
val3=[]
val4=[]
val5=[]
count1=0
acc_list=[]
acc_list1=[]
for pair in val_list:
if count1<20:
val1.append(pair)
elif count1<40 and count1>=20:
val2.append(pair)
elif count1<60 and count1>=40:
val3.append(pair)
elif count1<80 and count1>=60:
val4.append(pair)
elif count1<100 and count1>=80:
val5.append(pair)
count1+=1
# print(val1)
# print(val2)
crossval=[val1,val2,val3,val4,val5]
train_set=[]
for i in range(0,5):
test=crossval[i]
for j in range(0,5):
if j!=i:
for pair in crossval[j]:
train_set.append(pair)
# print('train set',train_set)
train_list=train_set
for i in range(len(train_set)):
if (train_list[i][1] == 1):
for word in train_list[i][0].split(" "):
positive_count[word.lower()] += 1
total_count[word.lower()] += 1
else:
for word in train_list[i][0].split(" "):
negative_count[word.lower()] += 1
total_count[word.lower()] += 1
# print(positive_count.most_common())
total_words=0
for pair in total_count.most_common():
total_words+=pair[1]
# print(total_words)
prob_all_docs={}
# stop_words=['','the','a','and','of','is','to','this','was','in','that','it','for','as','with','are','on','This','i']
stop_words=['']
for pair in total_count.most_common():
count2=0
if pair[0].lower() not in stop_words:
for sentence in train_list:
if pair[0].lower() in sentence[0].lower():
count2=count2+1
prob_all_docs[pair[0]]=count2/len(train_list)
# print('prob all docs',prob_all_docs)
num_of_positive_docs=0
# print('aa')
for pair in train_list:
if pair[1]==1:
# print('aa')
num_of_positive_docs+=1
positive_prob={}
for pair in positive_count.most_common():
count=0
if pair[0].lower() not in stop_words and pair[1]>3:
for sentence,label in train_list:
if pair[0].lower() in sentence.lower() and label==1:
count+=1
positive_prob[pair[0].lower()]=count/num_of_positive_docs
num_of_negative_docs=0
for pair in train_list:
if pair[1]==0:
num_of_negative_docs+=1
negative_prob={}
for pair in negative_count.most_common():
count=0
if pair[0].lower() not in stop_words and pair[1]>3:
for sentence,label in train_list:
if pair[0].lower() in sentence.lower() and label==1:
count+=1
negative_prob[pair[0].lower()]=count/num_of_negative_docs
prob_of_pos=num_of_positive_docs/len(train_list)
prob_of_neg=num_of_negative_docs/len(train_list)
smoothened_positive_prob={}
for pair in positive_count.most_common():
count=0
if pair[0].lower() not in stop_words and pair[1]>3:
for sentence,label in train_list:
if pair[0].lower() in sentence.lower() and label==1:
count+=1
smoothened_positive_prob[pair[0].lower()]=(count+1)/(num_of_positive_docs+2)
smoothened_negative_prob={}
for pair in negative_count.most_common():
count=0
if pair[0].lower() not in stop_words and pair[1]>3:
for sentence,label in train_list:
if pair[0].lower() in sentence.lower() and label==1:
count+=1
smoothened_negative_prob[pair[0].lower()]=(count+1)/(num_of_negative_docs+2)
count=0
count1=0
for pair in test:
pred,prob=predict(pair[0])
pred1,prob1=smoothened_predict(pair[0])
if pred==pair[1]:
count+=1
if pred1==pair[1]:
count1=count1+1
accuracy =count/len(val_list)
accuracy1=count1/len(val_list)
# print(accuracy)
acc_list.append(accuracy)
acc_list1.append(accuracy1)
avgacc=sum(acc_list)/5
avgacc1=sum(acc_list1)/5
print("average accuracy of 5 fold cross validation is: ",avgacc)
print('average accuracy of 5 fold cross validation using smoothening is: ',avgacc1)
average accuracy of 5 fold cross validation is: 41.46799999999937
average accuracy of 5 fold cross validation using smoothening is: 44.94599999999919
smoothened_negative_prob={}
for pair in negative_count.most_common():
count=0
if pair[0].lower() not in stop_words and pair[1]>3:
for sentence,label in train_list:
if pair[0].lower() in sentence.lower() and label==1:
count+=1
smoothened_negative_prob[pair[0].lower()]=(count+1)/(num_of_negative_docs+2)
print(smoothened_negative_prob)
{'the': 0.511002444987775, 'i': 0.8899755501222494, 'was': 0.2469437652811736, 'and': 0.37897310513447435, 'to': 0.20537897310513448, 'a': 0.9046454767726161, 'not': 0.044009779951100246, 'it': 0.28117359413202936, 'for': 0.09290953545232274, 'is': 0.3154034229828851, 'of': 0.10268948655256724, 'this': 0.13691931540342298, 'food': 0.12224938875305623, 'we': 0.17114914425427874, 'be': 0.16625916870415647, 'in': 0.4034229828850856, 'at': 0.32273838630806845, 'that': 0.05134474327628362, 'but': 0.044009779951100246, 'place': 0.10268948655256724, 'my': 0.08312958435207823, 'had': 0.06601466992665037, 'so': 0.20048899755501223, 'tasted': 0.004889975550122249, 'enjoy': 0.012224938875305624, 'business': 0.0024449877750611247, 'tasteless.': 0.0024449877750611247, 'live': 0.0024449877750611247}
smoothened_positive_prob={}
for pair in positive_count.most_common():
count=0
if pair[0].lower() not in stop_words and pair[1]>3:
for sentence,label in train_list:
if pair[0].lower() in sentence.lower() and label==1:
count+=1
smoothened_positive_prob[pair[0].lower()]=(count+1)/(num_of_positive_docs+2)
print(smoothened_positive_prob)
{'the': 0.529113924050633, 'and': 0.3924050632911392, 'was': 0.25569620253164554, 'i': 0.9215189873417722, 'a': 0.9367088607594937, 'is': 0.3265822784810127, 'to': 0.21265822784810126, 'this': 0.14177215189873418, 'great': 0.1341772151898734, 'in': 0.4177215189873418, 'of': 0.10632911392405063, 'good': 0.13924050632911392, 'very': 0.1189873417721519, 'for': 0.09620253164556962, 'food': 0.12658227848101267, 'with': 0.07848101265822785, 'place': 0.10632911392405063, 'my': 0.08607594936708861, 'are': 0.09873417721518987, 'we': 0.17721518987341772, 'it': 0.2911392405063291, 'you': 0.0759493670886076, 'amazing': 0.04556962025316456, 'family': 0.012658227848101266, 'never': 0.015189873417721518, 'prices': 0.02278481012658228, 'steak': 0.02531645569620253, 'once': 0.012658227848101266, 'spicy': 0.012658227848101266, 'quality': 0.015189873417721518, 'it!': 0.012658227848101266, 'sweet': 0.012658227848101266, 'that.': 0.012658227848101266, "can't": 0.012658227848101266}
Function for predicting the sentiment using laplacian smoothening
def smoothened_predict(sentence):
pos_prob=1
neg_prob=1
for word in sentence.split(' '):
if word.lower() in prob_all_docs.keys() and word.lower() not in stop_words:
# print(word)
if word.lower() not in positive_prob:
pos_prob=pos_prob*(1/(num_of_positive_docs+2))
else:
pos_prob=pos_prob*smoothened_positive_prob[word.lower()]
if word.lower() not in negative_prob:
neg_prob=neg_prob*(1/(num_of_negative_docs+2))
else:
neg_prob=neg_prob*smoothened_negative_prob[word.lower()]
# print(pos_prob)
# print(neg_prob)
pos_prob=pos_prob*prob_of_pos
neg_prob=neg_prob*prob_of_neg
if pos_prob>neg_prob:
return 1,pos_prob
else:
return 0,neg_prob
predicting sentiment of test data using smoothened(laplacian) predictor
test_list=test_set.values.tolist()
print(test_list)
count=0
for sentence in test_list:
# print(sentence[0])
pred,prob=smoothened_predict(sentence[0])
if pred==sentence[1]:
count+=1
print(pred,prob)
print('accuracy = ',count/len(test_list))
0 2.779690823252535e-10
1 5.274147398564804e-10
1 3.1526387000181787e-13
0 0.00012772375602095897
1 2.890385446147022e-18
1 7.17387468334148e-06
1 3.2603753192502035e-09
0 1.9685701113819558e-10
0 4.477091848446003e-15
1 4.4214895392952466e-08
1 0.0029665818255936367
accuracy = 0.68
Top 10 words that predicts positive: P[Positive| word]
import operator
#p[positive|word]p=[word|positive]*p[positive]/p[word]
p_pos_given_word={}
# print(positive_prob)
# print(prob_all_docs)
# print(prob_of_pos)
for word,prob in positive_prob.items():
p_pos_given_word[word]=positive_prob[word]*prob_of_pos/prob_all_docs[word]
sorted_prob=sorted(p_pos_given_word.items(),key=operator.itemgetter(1),reverse=True)
print("Top 10 words to predict positive: ")
for i in range(0,10):
print(sorted_prob[i][0])
Top 10 words to predict positive:
fantastic.
spot.
friendly.
perfect
fantastic
happy
amazing.
awesome
wonderful
delicious!
Top 10 words that predicts negative : P[negative| word]
import operator
#p[negative|word]p=[word|negative]*p[negative]/p[word]
p_neg_given_word={}
for word,prob in negative_prob.items():
p_neg_given_word[word]=negative_prob[word]*prob_of_neg/prob_all_docs[word]
sorted_prob=sorted(p_neg_given_word.items(),key=operator.itemgetter(1),reverse=True)
print("Top 10 words to predict negative: ")
for i in range(0,10):
print(sorted_prob[i][0])
Top 10 words to predict negative:
good
also
very
eat
good.
service.
made
night
really
some
References:
[1] https://miro.medium.com/max/1200/1*ZW1icngckaSkivS0hXduIQ.jpeg
[3] https://www.analyticsvidhya.com/wp-content/uploads/2015/09/Bayes_rule-300x172.png
{kind=link}